
什么是算力密度?
AMD近期发布了基于Zen 4c内核的Bergamo EPYC服务器CPU,单路最高128核心(256线程)的豪华配置与其说是为了应对Intel Sierra Forest(144核心)志强服务器CPU,不如说是应对ARM服务器CPU的进攻。ARM服务器CPU近期在单路性能上已经赶上甚至在某些Benchmark中超过了x86服务器CPU。以Ampere的AmpereOne为例,尽管单核性能还有很大差距,但其192核心的算力在安培的官方测评中已经超越了EYPC和Xeon CPU:

在AmpereOne号称云原生(Cloud Native)的众多特性中有两点比较有趣:没有睿频和没有超线程。与某些同学认为这是故弄玄虚不同,我倒认为这还真是符合云业务的部署需求,也和实际观察中一致:大量CSP在部署Xeon和EPYC服务器时,默认关闭睿频和超线程,防止出现性能抖动和不可预期。那么去除这两点,X86相比ARM服务器CPU,对它们最大的客户:CSP来讲,它会更加看重单核性能,还是单路性能呢? 对云厂商这种按照每VM出租收费的业务模式来讲,答案是显而易见的。如果单路能提供更多的性能,就能划分出更多的VM,进而可以产生更多的收入,这是云厂商的终极目标。相较而言,云厂商对单核性能和峰值性能并没有这么敏感,而ISA兼容性的问题在云厂商这种垂直整合的业态来说,也比较容易解决。那么重中之重,单路性能的制约瓶颈在哪里?如何衡量? 在衡量单路算力时,因为单路CPU内核Die有大有小,为了避免田忌赛马这种比较,这里引入算力密度概念,即在同等制程下,内核Die每mm²能提供的算力。算力密度,在摩尔定律步入末期的当下,尤其重要。算力密度高,单位Die在成本一样的情况下,就能产出更多的算力,进而获得更强的竞争力。在这个维度下,AmpereOne的算力密度似乎有领先的趋势,为了应对这种挑战,AMD和Intel交上了不同的答卷,也就是我们今天的主角:AMD Bergamo和Intel Sierra Forest。尽管两者面对的挑战相同,但技术路线却有很大不同,我们分别来了解一下。
按照惯例,以意大利城市命名的Bergamo(贝加莫),内核基于Zen 4c。这个小写c,缩写自Cloud,意味着云原生。和基于Zen 4的Genoa相比,CCD(Core Complex Die)从12个(Die Size 66.3mm²),减少到了8个(Die Size 72.7mm²),尽管Die Size增加了不到10%,但Die数目减少了33%,整体内核数目还进一步提升了33%(从96到128)!AMD官方数据对比了Zen 4和Zen 4c内核Die的大小:

Zen 4c相比Zen 4,内核Die缩小了35.4%,SmeiAnalysis网站提供了break down细节:
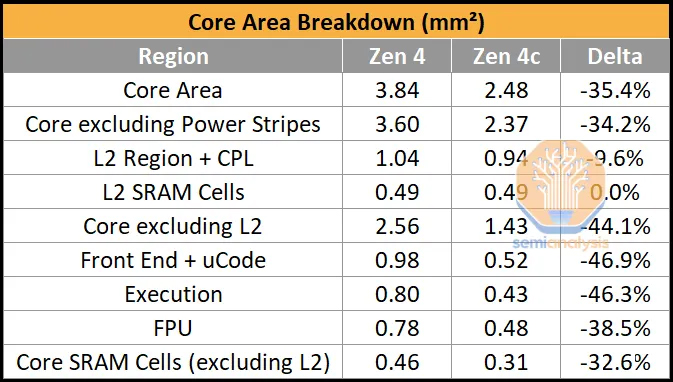
和Intel的路线明显不同,Zen 4c和Zen 4在ISA和特性方面(如超线程SMT)完全一样,甚至Zen 4c和Zen 4共用RTL代码!那么AMD是如何做到同样内核逻辑设计,面积减少了35.4%的呢?
秘密就在Zen 4c的后端设计中,对此SmeiAnalysis做了详细分析 ,有兴趣的同学推荐仔细阅读,简单来讲,贡献最大的是Zen 4c的目标频率更低,这样物理设计的时候,时序和功耗约束更小,设计的更加紧凑;第二是不同于Zen 4的模块化设计,Zen 4c的物理设计更加紧凑,更类似ARM的物理设计;最后是SRAM设计更加紧凑。如此,达到同样RTL的情况下,算力密度增加的结果:
与AMD不同,Intel在此布局的更早,技术路线也大为不同,算力密度更高。
Intel与ARM的战斗已经持续了二十多年,尽管进攻手机的战略完全失败,但ATOM这种能效更好的设计却无心插柳,在台式机和服务器中大放异彩。也许大多数同学对于在酷睿中的能效核和性能核的混合设计早有了解,对于ATOM在服务器中的应用知之不多。其实,基于ATOM内核的服务器也已经发售了十来年,但更多地是面向存储密集型和IO密集型的Micro Server,主要是和ARM的类似微服务器竞争。随着ARM开始进入高性能计算领域,ATOM Server这种算力低下的产品显然不够打的,必须提供更多的内核。Intel将高性能计算Xeon也划分了两个路径:

基于Core设计的大核GNR系列继续沿着单核性能路径演进,而ATOM小核则在Sierra Forest(SFR)中开始沿着算力密度高的方向演进,将会提供更多的算力密度(Perf/Area)。 与AMD公用RTL,只在后端设计中优化不同,SFR用到的ATOM核(现在叫做能效核),前端设计就已经为性能进行了优化,后端设计也当然进行了改进,目标只有一个,提供更高的算力密度。那到底提高了多少呢? SFR预计在2024年上市,提供144个E-Core,它的算力密度现在还不是很清楚。但我们可以从12代酷睿P-Core和E-Core的Die大小对比来推测:

因为L2 Cache二者一个是共享一个是独享,是个干扰因素,需要去除。去掉L2 Cache后,P-Core Golden Cove内核大小是5.55mm²;去掉L2 Cache,E-Core Die Size是1.70mm²。两者相差3.26倍!大家可以和Zen 4、Zen 4c比较一下,似乎在制程一致的情况下,预计SFR将会提供更高的算力密度。
联系电话:400-028-6620 028-85047200
公司地址:成都市武侯区一环路南二段2号新世纪商业中心东楼17楼B座